자료형이 무엇일까요? 자료형은 데이터를 표현하는 기준으로 변수 선언시 사용됩니다.
변수는 데이터 저장을 위해 할당된 메모리 공간에 붙여진 이름이라고 설명한 적이있습니다.
그럼 그 메모리 공간은 어떻게 할당할까요?
자료형은 다음 기준에 따라 선택하시면 됩니다.
-정수를 저장할 것인가, 실수를 저장할 것인가?
-데이터를 저장하기 위해서 몇 바이트의 메모리를 사용할 것인가?
당연히 바이트의 크기가 커질 수록 표현할 수 있는 데이터의 크기도 증가합니다.
위 기준에서 정수를 선택하고 4바이트를 사용한다면 그 때 사용하는 자료형이 바로 int입니다.
int num; //4바이트 크기의 정수형 변수 num선언
이걸 간단히 int형 변수 num이라고 부를 수 있습니다.
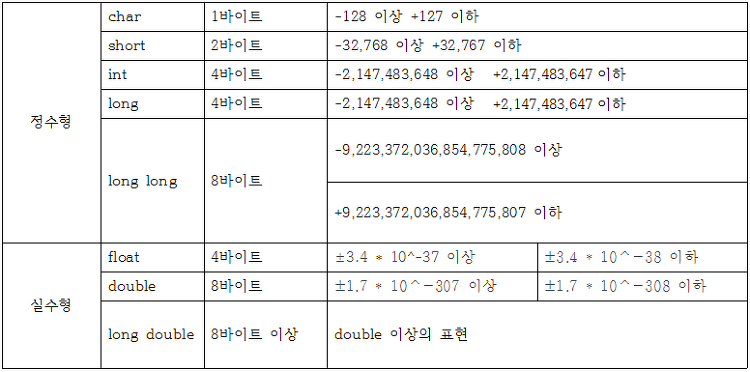
C언어에는 여러 가지 자료형이 있습니다.
아래 표는 각 자료형의 크기와 표현범위입니다.

보시다시피 바이트 크기가 커질수록 값의 표현범위가 커지는 것을 확인할 수 있습니다.
char 자료형은 1바이트(8비트)이므로 나타낼 수 있는 데이터의 종류 수가 2^8=256개입니다.
-128 ~ 127까지는 총 256개의 수가 있죠?
C의 표준을 정하는 ANSI에서는 자료형의 크기를 다음과 같이 표준화하고 있습니다.
"short와 int는 최소 2바이트이되, int는 short와 같거나 더 커야한다."
이 말은 자료형 별 크기를 정확히 제한하고 있지 않다는 것인데요, 자료형의 크기는 컴파일러마다 다른데 위 표는 VC++(Visual C++)를 기준으로
작성된 표이므로 일부 컴파일러와는 약간 다를 수 있습니다. 그러나 그 차이가 크기 않으므로 위의 표를 기준으로 공부하셔도 좋습니다.
그런데 뭐하러 이렇게 많은 자료형을 제공하고 있을까요?
자료형의 종류가 많은 이유를 설명해드리겠습니다.
첫째로 데이터를 표현하는 방법이 다르므로 정수 자료형과 실수 자료형으로 최소 2가지 이상은 필요합니다.
하지만 위의 표를 보를 보시다시피 자료형의 종류는 2가지보다 많습니다.
그리고 그냥 엄청 큰 long long하나만 있으면 될텐데 뭐하러 여러 가지 크기가 필요할까요? 다음 이유 봅시다.
둘째로 메모리의 효율적인 사용을 위해 여러 크기의 자료형이 필요합니다.
예를 들어 2바이트인 short크기의 변수가 1만 개 필요하다고 하면 종 2 * 10000크기인 20000바이트가 필요하죠.
그런데 그냥 long long으로 갖다가 선언하면 80000바이트가 필요합니다.
메모리 낭비죠.
자료형의 크기는 sizeof연산자를 이용해서 확인할 수 있습니다.
이 연산자의 피연산자로 변수, 상수도 올 수 있고 자료형의 이름도 올 수 있습니다.
사용법은 다음과 같습니다.
피연산자를 모두 소괄호로 감싸줬는데, 소괄호는 int같은 자료형 이름에는 필수이지만 나머지 피연산자에는 선택입니다.
하지만 무조건 소괄호를 사용하는 것을 권장합니다. 실제로도 이게 일반적인 방법이고요.
예제 봅시다.
실행 결과
VC++상의 실행결과는 보시면 int와 long은 크기가 같다는 것을 알 수 있습니다.
하지만 정확히는 "long이 int보다 크거나 같다"이므로 완전히 동일하지는 않지만 편한게 그냥 동일하다고 생각하셔도 큰일 나지는 않는답니다.
다음으로 정수를 표현하기 위한 자료형의 선택 방법에 대해 알아보겠습니다.
정수 12를 저장하기 위해 어떤 자료형을 선택해야 할까요?
아무래도 1바이트이니 메모리를 효율적으로 사용하게 char형?
정답은 상황에 따라 다르다 입니다.
즉 값의 범위만으로 자료형을 결정할 수 없는거죠.
예제 보시죠.
실행 결과
보시는 것처럼
printf("num1 + num2 크기: %d \n", sizeof(num1 + num2));
printf("num3 + num4 크기: %d \n", sizeof(num3 + num4));
이 문장은 좀 다른 결과를 보입니다.
char형 끼리 연산을 하면 1바이트, short형 끼리 연산을 하면 2바이트가 출력 될 줄 알았지만 둘 다 4바이트가 출력되었습니다.
그 이유는 CPU가 처리하기 가장 적합한 크기의 정수 자료형은 int형 이기 때문입니다. 따라서 int형 연산 속도가 다른 자료형 연산속도에 비해 더 빠릅니다.
그래서 int보다 작은 크기의 데이터는 int형으로 바뀌어서 연산이 진행됩니다. (자료형을 변환하는 것을 '형 변환'이라고 하는데 이는 다음 강의에 배울거에요. 그리고 왜 int형이 다른 자료형에 비해 빠른지도 다음 강의에서 배웁니다.)
그럼 저 두 문장에서 4바이트가 출력 된 이유를 이제 알겠죠?
정리하면, 연산의 횟수가 빈번한 변수를 선언하는 경우에는 int형 변수를 선언하는 것이 좋다는 것입니다.
그럼 char와 short는 필요하 없는것처럼 느껴지실 텐데, 아닙니다.
이 들도 나중에 매우 유용하게 사용됩니다.
다음은 실수를 표현하기 위한 자료형 선택 방법에 대해 알아보겠습니다.
실수 데이터가 표현할 수 있는 범위는 매우 넓습니다.
따라서 실수 자료형을 선택할 때 표현범위는 중요하지 않습니다. 그러면 무엇을 보고 선택해야할까요?
바로 '정밀도'입니다. 실수는 오차가 발생한 다고 했는데요, 바이트의 크기가 커질 수록 오차도 줄어듭니다.
참고로 float형은 6자리 double형은 15자리 long double형은 18자리까지 오차가 발생하지 않음을 보장 할 수 있습니다.
그런데 정수형에서는 int를 보편적으로 선택하였는데 실수형에서도 그런게 있을까요?
네 있습니다. 바로 double형입니다. float는 정밀도가 낮은 편이고 long double은 부담스럽기도 하기 때문입니다.
예제 보시죠
실행결과
보시듯이 scanf로 double형 데이터를 입력받을때는 %lf라는 서식문자를 사용합니다.
출력할 때는 %f를 사용하고요.
자료형 앞에 unsigned를 붙이면 0이상의 정수만 표현하게 할 수 있습니다.
장점은 데이터의 표현범위가 양수로 두 배 더 넓어지게 됩니다.
char 같은 경우는 원래 범위가 -128 ~ +127이었지만 unsigned를 붙이면 0 ~ +255까지 표현 할 수 있게됩니다.
unsigned를 붙이게 되면 가장 왼쪽비트 즉 MSB까지 데이터를 표현하는데 사용됩니다.
unsigned는 정수 자료형 앞에만 붙일 수 있습니다.
또 정수 자료형 앞에 signed를 붙일 수도 있습니다만 딱히 의미는 없습니다. int나 signed int나 똑같은 선언이죠.
그래서 대부분 signed는 생략합니다.
참고로 char형은 컴파일러마다 다를 수 있습니다.
다른 정수 자료형들과 달리 char는 signed char와 다를 수 있습니다.
char를 unsigned char로 처리하는 컴파일러가 존재하기 때문이죠. 이런 경우에는 char에 음의 정수를 저장하기 위해 signed를 붙이기도 합니다.
마지막으로 문자를 표현하는 방법에 대해 배우겠습니다.
여태 우리는 수를 표현하는 방법에 대해 배웠는데요 하나 빠진게 있죠? 바로 문자 표현입니다.
문자는 어떻게 표현 할까요? 컴퓨터는 숫자를 이용해서 무언가를 표현합니다. 따라서 우리는 숫자를 이용하여 문자를 표현해야합니다.
그럴 때 필요한 것이 '아스키 코드'입니다!
아스키 코드는 숫자를 이용하여 문자를 표현하도록 숫자를 문자에 연결하여 표현한 코드입니다.
'A'는 아스키 코드로 65이고 'B'는 66입니다. '(작은 따옴표)는 아스키 코드로 96이며 ~문자는 126입니다.
이 처럼 프로그램상에서는 문자표현에는 작은 따옴표가 사용됩니다.
예제 보시죠.
실핼 결과
%c라는 서식문자는 문자의 형태로 데이터를 출력, 입력 하라는 의미입니다.
그리고 아까는 int형 연산이 빠르다고 했는데 문자도 int형 변수에 저장해야 하는 것 아닌가? 라는 분도 계실 겁니다.
하지만 int형으로 선언하였을 때는 '연산'속도가 빨라지는 것입니다.
하지만 A + B 처럼 문자끼리 연산을 할 필요는 없지요. (물론 가능은 합니다)
아스키 코드 값은 0이상 127이하로 이루어져 있으므로 문자를 '저장'하는데에는 int형 변수보다 char형 변수가 더 적합합니다.
char형은 그럼 문자형인가 정수형인가 헷갈려하시는 분이 계신다면 답은 '정수형'입니다.
실제로 저장되는 값은 정수이기 때문입니다. 헷갈리시면 안되요!
아스키 코드 표를 제시하고 이번 강의를 마치겠습니다.

다음 강의는 상수와 형 변환에 대해 다룹니다.
다음 강의 때 뵙겠습니다.